
深度神经网络的由来:
感知学习算法(perceptron learning algorithm)
↓
深度神经网络(deep neural networks)
神经元的模型:
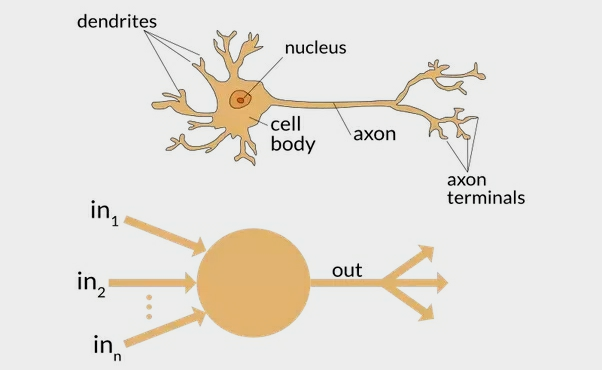

- y=wx+b
- y:模型预测的输出
- w:模型的权重(可训练)
- b:水平移动偏差(intercept截距)
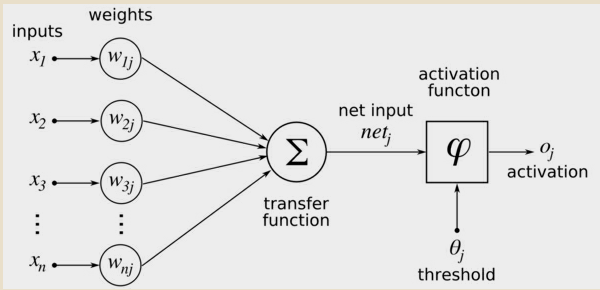
第一次输入时,w是一个随机得非常小的权重,特征值(x)与权重相乘,计算结果与输入线性求和,求和的值馈送到激活函数,这个激活函数是一种感知习学算法的单位阶跃函数(unit step function)。然后单位阶跃函数基于同值将样本分成类。通过模型计算的数据点>0分为一类,<0分为第二类。对每一个预测分类,查看是否正确,如果正确则绘一个正确的分类标签,如果获得正确的分类,则不更新该样本的相关权重。
然而在错位的分类的情况下,它以同样的方法更新权重,这样可以将计算推向正确的类,是后期训练传递中,很可能正确预测该特定类的标签。
感知学习算的简单性也有几个缺点(drawbacks)。因为我们假设在空间中汆在一组权重来充分地分类。其次,我们还假设数据集可线性分离为不同的类。
取而代之,为了模拟更复杂的函数,我们需要利用非线性的激活函数,因为它们本身就能否进行更复杂的表示,
尽管感知器学习算法存在局限性,但它启发了后来的模型,这些模型包括更多的神经元,非线性激活函数和称为梯度下降的不同类型的学习规则。
激活函数
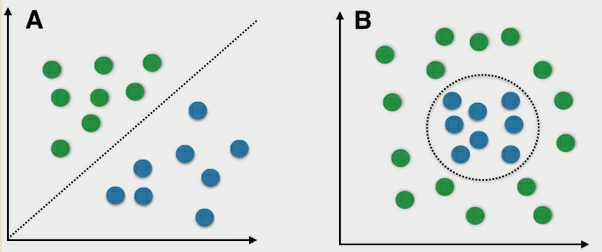
非线性激活函数的作用是执行一个坐标到另一个坐标的几何变换。如上图,图A代表一个线性分隔的二进制分类预测,它代表着我们可以找到一条直线来正确分离两个类。像我们讨论过的感知器学习算法这样的线性分类器可以处理这种情况,因为数据的性质使得可训练的参数(权重)来学习,因为这是一个简单的线性分类问题。 然而,对于图B,我们需要一种能够对数据点进行分类的更强大的表示,因为这不能通过使用直线来实现。 这就是使用非线性激活函数的原因,因此也可以学习这些更复杂的数据分布。
在深度神经网络中使用了几种非线性激活函数来实现线性判断,例如S形,双曲正切函数,线性整流单元等。
sigmoid激活函数(S激活函数)

主要用于二进制的分类任务,其中有两个互斥的类。它主要是将各种可能性的值压缩到一个连续且有界的较小范围内。由于sigmoid是一个连续函数,它具有可微分的优点,即我们可以采用导数并在深度神经网络训练期间将其用于反向传播。如果专注中间段,基本上有一个直线分类器,如果考虑曲线的早期分布,则可以建模指数部分。sigmoid是深度学习中最重要的激活函数之一。
Hyperbolic Tangent Activation Function双曲正切激活函数
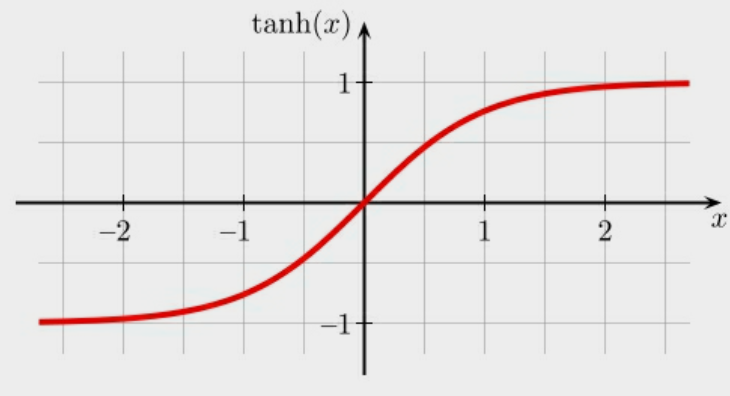
双曲正切激活函数也称作“tanh”,特别是在Recurrent Neural Networks(递归神经网络)。它可以看做是sigmoid激活函数的变化且有更加广泛的输出值域。与sigmoid类似,出入线性的计算结果,再将值的形式转变为-1到1的区间。对于二进制的分类问题,值域可设置为0,输出值大于0为正类,输出值小于0为负类。在实践中,tanh激活正确函数通常的逻辑函数收敛做得更快,并且不太容易在神经网络后续层中过渡拟合。
Rectified linear Unit Activation(ReLU)Function 线性整流函数
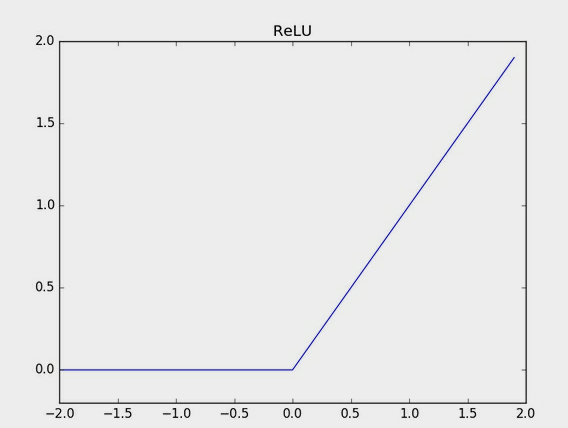
在深度神经网络中,线性整流函数(ReLU)已成为隐藏层中激活函数的标准。因为于其它函数相比(如sigmoid,tanh等)它的实践表现更好。主要的有点事用ReLu在隐藏层中作为激活函数,在训练期间梯度消失的趋势更小。梯度消失现象是当下游传播的梯度变得非常小,以至于早期层不再学习,因为后面的层已经知道了。这个问题容易被忽略,并且在训练 层深度网络时变成一个巨大的问题。线性整流函数由于其归零为负值的性质可以解决这个问题。输入到线性整流函数是线性计算步骤的结果。如果输入是负数,ReLu的输出结果是零,但是如果是正数,它将值保留为激活函数的输出。线性整流函数是0到最大值的网络输入。
f(Z)=max(0-Z)
与sigmoid不同,ReLu不会受到最大值饱和的影响,整流线性单元激活函数的值可以尽可能的大,只要它们是正的。在实践中使用的ReLU还存在其它的修正形式。例如,LeakyReLu它允许最小范围的负值减少,如max(0.Z,Z),随机整流线性单元,参数整流线性单元类。
A Feed Forward Neural Network前馈神经网络
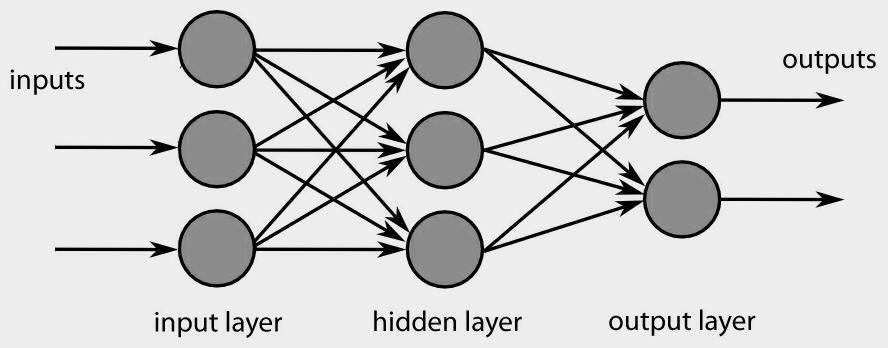
现在我们人工神经元,感知器学习算法和激活函数有了很好的理解,现在是时候将我们学到的东西组装成一个称为前馈神经网络的新模型结构。
前馈神经网络是一个人工神经网络,它由几个层组成,其中包含单向晶格结果中的神经元。
这意味着网络的组成并不是以循环的方式所建成的,故名前馈。前馈神经网络有时也被称作多层感知器(Multi-Layer perceptron)MLP。MLP与感知学习算法的不同之处在于前者是由多层,多个神经元构成,并通过梯度下降使用反向传播算法来训练网络。前馈神经网络由三层组成,输入层、隐藏层和输出层。
上图被称作2层前馈神经网络。传统上,在描述一种人工神经网络中的层数时,不计算输入层。
输入层包含以信息特征形式的数据点以馈送到网络中。箭头代表着网络的权重。通过箭头可以观察到一层中的神经元连接到下一层中的每个神经元。由于这样的连接性质,这些层被称作完全连接层(fully connected layer)或密集层(Dense layers)。前馈神经网络的隐藏层是真实学习发生的地方,因为输入特征从一个表示转换到另一个表示,以便可以学习它们的基础模式。隐藏层之所以被称为隐藏层是因为无法直接发现内部如何运作。

