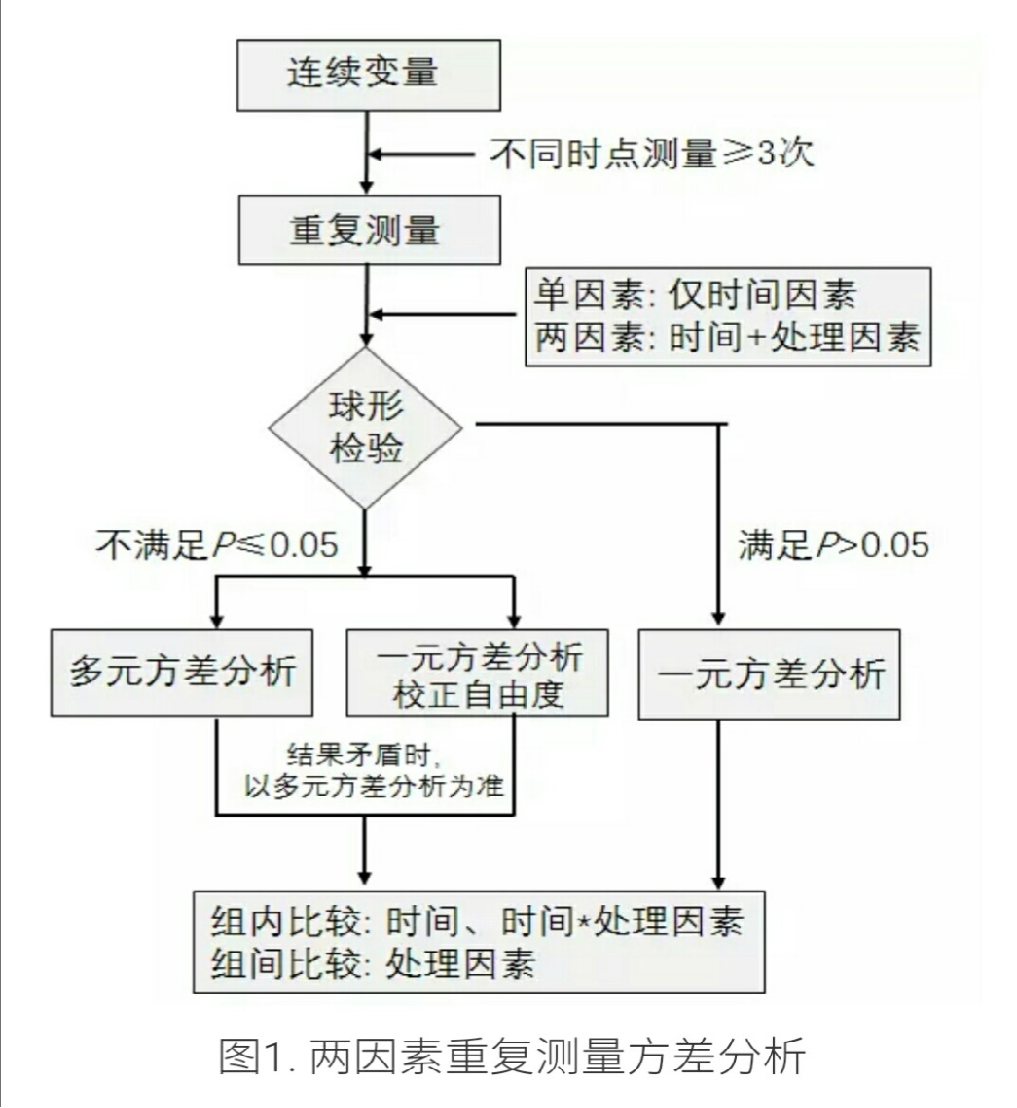
LME线性混合模型处理ERP
存在的问题
- 时间窗口的选择
- 通道的选择
- 模型的选择
- 变量编码
- 统计能力 power
文献1--线性混合效应模型在婴儿和儿童事件相关潜力研究中的效用
根据论文《线性混合效应模型在婴儿和儿童事件相关潜力研究中的效用》[1]的处理过程找到了GitHub上的数据处理脚本。脚本共有7个,其中1-5是Matlab从Continues EEG到ERP的处理过程,脚本6-7是R语言对ERP进行LME混合线性模型的处理过程,如Figure 1。

文章比较ANOVA与LMM,发现ANOVA的结果有偏差,随着受试者的减少,结果变得偏差。而LMM随着受试者的减少,模型也能产生准确、无偏差的结果。论文包括了教程和示例代码。
文献2--线性混合效应模型和非独立数据的分析:一个统一的框架,用于分析改变主题内部和/或项目内的分类和连续自变量。
近年来,对“线性混合效应模型” (LMEMs)的兴趣急剧增加。Judd、Westfall 和 Kenny(2012 年)以及Barr、Levy、Scheepers 和 Tily(2013 年)的有影响力的文章清楚地表明,许多心理学研究都需要这些类型的模型。[2] 传统的 ANOVA/回归方法的局限性在于它不能很好地处理缺失的数据,并且无法处理在“单位”内变化的连续预测变量(例如,受试者内、组间、组内、教室)。更重要的是,当相同的受试者暴露于同一组项目(或刺激或目标)时,这种方法会产生有偏差的推论统计。只有混合模型才能产生具有可接受的 I 型和 II 型错误率的无偏参数估计。(也就是说ANOVA不适合重复测量)
术语和数据格式
线性混合效应模型(LMEM)指代具有一种或多种的随机效应的模型,如分层回归、分层线性建模
(HLM)、多级回归、多级线性建模、线性混合模型和随机系数模型。
为了采用“
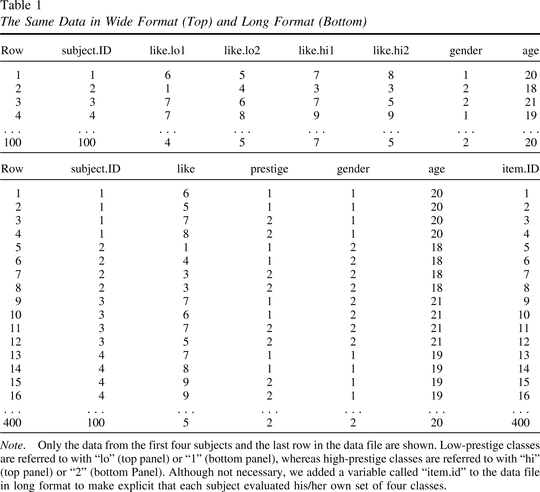
LMEM思维方式”,越来越多的研究人员现在以“长格式”而不是“宽格式”分析他们的数据。
长格式的数据文件更“整洁”,因为它们类似于受试者间设计:一列表示因变量,一列或多列对应于预测变量些,并且一项观察与一行相关。R中的
reshape
函数允许研究人员将数据文件从宽格式转换为长格式,反之亦然。
想象一个假设的实验(我们将在本文中将其称为“研究
1”),其中研究人员招募100名本科生,并要求他们列出他们在大学学习的两个高声望课程和两个低声望课程。声望被定义为课程在学生成绩单上“看起来不错”的程度(例如,困难的科学课程、荣誉课程、研究生水平的课程)。然后要求学生在9分制上表明他们对四个班级中的每一个课程的喜好。(Figure 2)
线性混合模型简介
固定变量和随机变量
在LMEM中,相关变量被认为是“固定的”(fixed)或“随机的”(random)。在“研究1”中的声望(prestige)就是一个固定变量,且有两个级别,而受试者(subject.ID)就是一个随机变量(有100个级别)。
- 当从感兴趣的变量的所有级别收集数据时,变量被认为是固定的。
- 当一个变量具有许多可能的水平并且研究人员对所有可能的水平都感兴趣时,该变量被认为是随机的,但数据中仅包含水平的随机样本。
- 测量的预测因素,协变量和人口统计通常是固定的变量。
- 仅当每个变量级别的观察值多一个以上的观察值时,数据分析中才会明确包含随机变量。只有在数据中创建非独立性时,随机变量才包含在分析中。
简单误差 VS 复杂误差
统计分析都具有相同的基本结构:\(DATA = MODEL + ERROR\)(Figure 3)。每个统计模型都基于结果变量(\(β0\))和一个或多个预测变量(此处为\(β1X\))的(加权)平均值进行预测。独立数据分析(例如,受试者间分析)和非独立数据分析(例如,受试者内分析)之间的主要区别在于误差项的复杂性。
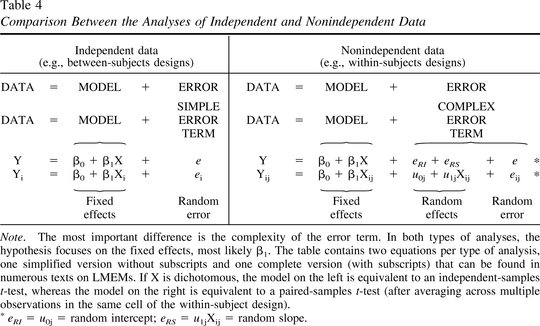
在独立数据分析中(受试者间),误差项比较简单,只有一个随机误差(\(e_i\))。Figure 3左
当数据是非独立的(受试者内)并通过LMEM分析时,误差来源于三个分量。Figure 3右
- 随机截距:来源于受试者之间的个体差异(Figure 3中标记为\(e_{RI}\) 或 \(u_{0j}\) )
- 随机斜率:来源于受试者之间受预测变量(除了受试者的其他变量)影响的差异(Figure 3中标记为\(e_{RS}\) 或 \(u_{1j}X_{ij}\) )
- 随机误差:其他误差来源。(Figure 3中标记为\(e\) 或 \(e_{ij}\) )
在GLM(一般线性模型)中的重点是解释与预测变量的相关回归系数。在Figure 3中,β1表示模型对“声望”对喜欢的影响的估计。如果β1在统计上显着,我们得出结论,预测变量对结果变量有影响。
固定效应与随机效应的解释
- 固定效应:在Figure 3中的两个模型中,系数β0和β1称为“固定效应“。β1为固定斜率,β0为固定截距。这些影响称为“固定",因为它们适用于整个样本。
- 随机效应:在Figure 3中的两个模型中,系数\(u_{0j}\) 和 \(u_{1j}X_{ij}\)称为“随机效应“。\(u_{1j}X_{ij}\)为随机斜率,\(u_{0j}\)为随机截距,因为他们代表了模型中β0和β1在不同受试者间的变化程度。在Equation 1中更容易理解。
\[Y_{ij} = ( \beta_0 + u_{0j} ) + ( \beta_1 + u_{1j} ) X_{ij} + e_{ij}\qquad{(1)}\]
扩展到具有多个二分预测变量的设计
与方差分析和回归分析一样,当模型包含交互项时,LMEM 通常要求我们在分析之前将预测变量居中。更准确地说,只有当二分变量已被重新编码为 -.5 和 +.5(或以零为中心的任何其他两个值)并且连续变量已经“平均居中”(通过从每个分数中减去平均值)。
连续受试者内预测变量的分析
LMEM可以轻松扩展到连续变量间(内部)的分析(例如:受试者间,课程间)。
不同形式的均值居中
尽管预测变量在研究 1 和 2 中都以零为中心,但两者之间存在重要区别:在研究 1 中,二分预测变量被重新编码为 -.5 和 +.5,并且不需要重新编码,因为它不会影响与预测变量相关的固定效应的参数估计。然而,在研究 2 中,连续预测变量以每个受试者自己的均值为中心(有时称为“聚类均值居中”或“组均值居中”)。这种操作对于获得预测变量和结果之间的主体内关联的无偏估计是必要的。
相关分析
LMEM框架还可以用于检查连续的受试者间预测因子与一个或多个其他预测变量的交互作用。
如果预测变量是在受试者内,应该聚类平均值居中(cluster-mean),
Figure 4。

如果预测变量是在受试者间,应该以总平均居中(grand-mean), Figure 5。

请注意,受试者内的连续预测变量可以是时间,以便模型可以检查受试者随时间的变化。
扩展到多级模型
在到目前为止讨论的所有示例中,预测变量在 受试者中各不相同。读者应该知道,上面所说的一切(以及文章的其余部分)也适用于预测变量在高阶单元或“集群”内变化的研究。例如当受试者嵌套在一个组(groups)、家庭(families)、或者教室(classrooms)。所谓的“多级模型”只是LMEM的一个特例。
多级模型示例
考虑一项研究,其中研究人员组成四个人的讨论组,并为其中两个人分配一个高地位(高声望)和两个低地位(低声望)。(有一个小的变化:主题.ID 被替换为 group.ID)。受试者和组都是随机变量。鉴于每个受试者只有一次观察,LMEM 不包含副主题随机效应。它确实包含两个组的随机效应:一个逐组随机截距(因为来自同一组的四个数据点是相关的)和一个逐组随机斜率(因为预测变量“声望”在组内变化 )
限制最大似然
应该注意的是,LMEM 使用称为“限制最大似然”(ReML)的估计程序,而不是作为标准 ANOVA 和回归分析的“普通最小二乘法”(OLS)。 使用 ReML 作为估计程序有许多 LMEM 用户应该注意的含义。除了在简单的 LMEM 中,最终模型可能具有带小数的分母自由度。它们应该这样报告,例如,F (1, 54.17) = 4.86, p < .04。 只有 Kenward-Roger 自由度的F统计量的结果才能准确再现重复测量方差分析的结果。
非独立的多重来源
在许多心理学实验中,受试者会接触到相同的一组项目,即他们可能会查看相同的单词、句子、图片或头像,或者他们可能会对相同的产品、面孔、艺术品或个人进行评分。或者,聚集在组、家庭、教室或县中的受试者可以各自提供多个数据点。此类研究包含两个非独立性来源:一些回答可能更相似,因为它们是由同一受试者做出的,其他回答可能更相似,因为它们涉及相同的项目(即不同的受试者对相同的项目进行评分),但其他反应可能更相似,因为它们是由同一组的受试者做出的。
当存在多个非独立来源时,可能很难决定分析中应包括哪些随机效应。
然而,幸运的是,所有专家都同意数据分析的初始步骤。
第一步包括确定研究设计所要求的所谓“最大随机效应结构”。正如我们将看到的那样,这个最大随机效应结构包括我们可能希望根据设计特征包括的所有随机效应,即基于预测变量是否在导致非独立性的随机变量的水平之内或之间变化数据。
第二步包括估计具有最大随机效应的LMEM结构体。然而,正如我们将看到的,这并不总是可能的,因为一些 LMEM 非常复杂,以至于迭代估计过程无法收敛。
在这种情况下,有必要逐步简化随机效应结构,直到可以实现收敛。
在接下来的部分中,我们将详细讨论前两个步骤中的每一个。在我们的讨论中,我们将关注两个导致数据不独立的随机变量。第一个随机变量始终是主题。我们将第二个随机变量称为“项目”,但读者应该知道,这个术语可能指的是任何随机变量,它是非独立的第二个来源(例如,刺激、目标、同盟者、位置、小组、教室)。
如何确定最大随机效应结构
随机截距
通过在最大随机效应结构中确定适当的随机截距来解释其非独立性。Figure 6中的第一条规则确定了什么时候需要随机截距。当考虑的单元是受试者时,只要给定受试者多个数据点(测试点),就应该包括一个由受试者产生的随机截距。 当每个受试者有多个数据点并且每个项目有多个数据点时,必须通过添加按受试者随机截距和按项目随机截距来考虑这两个非独立来源。

第一个规则:如果单元引起非独立性,则需要一个串联随机截距。
第二个规则:通常,单位内预测变量需要一个串联随机斜率,而单位间预测器则不需要。
第三个规则:建议在包含交互的所有因素均为单位内部时,包括一个串联随机斜率,以进行相互作用。
随机斜率
随机斜率参见Figure 6中的第二个规则。我们希望为在受试者内变化的任何预测变量包括一个按受试者随机斜率(但不是在受试者之间变化时)。同样,我们希望为在项目内变化的任何预测变量包括一个逐项随机斜率(但不是在项目之间变化时)。
- 在受试者间变化的研究
为了说明这个规则,让我们想象一个研究,在该研究中,受试者评价他们对八辆低声望汽车和八辆高声望汽车的喜好。所有受试者都对同一组 16 辆汽车进行评分(Figure 7)。 请注意,声望的随机斜率不需要随机斜率,因为声望在项目内不会变化(每辆目标汽车的声望要么低要么高)。

- 在项目内变化的研究
想象一项研究,其中受试者评估同一组 20 辆汽车(中等声望),但他们在两个受试者之间的条件之一中这样做。一半的受试者在看过五辆声望很高的汽车(高声望背景)后评价他们对这 20 辆车的喜好,而另一半受试者之前曾接触过五辆声望很低的汽车(低声望背景)。同样,这项研究包含两个非独立性来源,主题和项目,需要两个随机截距。预测变量“声望”在受试者之间变化(每个受试者仅在一个声望上下文条件下),但在项目内变化(20 辆目标汽车中的每一辆在某些受试者的声望较高的上下文中,但在某些受试者的声望较低的上下文中其他科目)。适当 LMEM的最大随机效应结构包含三个随机效应(参见Figure 8)。鉴于声望(背景)因学科而异,因此无需包括副学科 声望的随机斜率。

交互的随机效应
关于交互,参见Figure 6中的第三条规则。当交互作用的所有预测变量在受试者内变化时,交互项的逐受试者随机斜率应包含在最大随机效应结构中。同样,当交互项的所有预测变量在项内变化时,研究人员应该为交互项包括一个逐项的随机斜率。除了前两条之外,这条规则允许我们为更复杂的设计确定最大随机效应结构。
如何解决收敛问题
在确定了研究的最大随机效应结构后,下一步是估计相应的 LMEM。不幸的是,导出参数估计的迭代 ReML 过程并不总是“收敛”(即,数值优化算法不能可靠地确定对数似然函数的最大值)。如果模型无法收敛,可以使用Figure 9中的方式补救。

预防措施避免收敛失败:
1. 在您的研究中包括尽可能多的受试者和尽可能多的项目。
2. 包括异质受试者和异质物品。解决收敛失败的非感性补救措施:
3. 检查您的数据(案例分析,分配假设)。如有必要,将转换应用于预测变量或结果变量。
4. 检查模型拼写错误(例如,该模型是否包含一个在单位之间变化的预测变量的字节单位随机斜率?)。
5. 确保所有预测因素都居中(降低了多重共线性)。
6. 增加迭代次数。
7. 更改用于最大化对数似然函数的数值优化过程。
8. 给模型更好的启动值。
9. 重建预测变量或结果变量。
10. 检查非关联是否是由于存在一些特定细胞的少数受试者(或项目)。如果是,请考虑归纳数据或删除有问题的主题(或项目)。
11. 去除协变量的随机效应(只要协变量与感兴趣因素之间的相互作用不在模型中)。
12. 检查您的模型是否可以简化:如果假设是x2 by x2相互作用,则可能无需在模型中包含x3和x4(至少最初)。或在一组高度相关的预测指标中删除除一个预测因子以外的所有预测变量。解决融合失败的经典疗法:
13. 如果目标是测试两个固定效果X1和X2,而不是它们的相互作用,则估计两个LMEM,一个均具有固定效果,但仅是X1的随机斜率(用于测试X1),一个具有两个固定效果,但只有X2的随机斜率(用于测试X2)。
14. 如果您的设计具有两个或多个单元内预测因素,并且您的假设涉及互动,请删除单位内预测变量和低阶相互作用的串联随机斜率,但请勿删除副本UNIT单位内预测变量之间的最高阶段相互作用的随机斜率(Barr,2013,Frontiers)。
15. 在随机效果之间有选择地删除协方差:首先删除与您的假设无直接相关的预测因子的协方差(如果您决定将这些预测变量保留在模型中)。继续删除您怀疑无论如何都接近零的协方差。最后,消除随机效应之间的所有协方差。
16. 删除模型中也有随机斜率的一些随机截距。请勿删除随机斜率。警告您的读者,您估计了一个没有随机拦截的模型。
17. 执行两个单独的LMEM-一个主体作为分析单位(具有最大的受试者随机效应结构,但没有副本随机效应),一个用作为分析单位的项目(具有最大的副总体随机效应结构,但没有受试者随机效应)并应用F1 F2逻辑(两者都必须在p .05处显着)。具有重大缺点的纠正措施:
18. 运行分析并计算Clark(1973)Min-F'统计数据。请注意,该测试的功能不足。如果Min-F’很重要,您可以确信您的结果不是由于I型错误率而引起的。
19. 运行LMEM或重复测量方差分析,其中受试者是唯一的随机变量(因此忽略了由于项目而引起的非独立性)。警告您的读者,您的I型错误率可能高达60%(请参阅Judd等人,2012年的表2)。
20. 估计您保持随机的LMEM
决定要估计的LMEM
在前面的部分中,我们已经描述了分析LMEM 的前两个步骤。第一步是确定研究设计所需的最大随机效应结构。第二步是让 LMEM 在保持随机效应结构尽可能大的同时收敛。 大多数专家一致认为,最终的 LMEM 需要包含作为研究人员假设重点的预测变量的随机斜率,而不管这个(这些)随机斜率的方差如何。他们还同意,随机效应结构中方差接近于零的方差分量的存在不会影响模型的拟合优度。因此,无论它们是包含还是排除,对固定效应的显着性检验的影响都非常小。
统计能力与普遍性
在大多数 LMEM 中,预测变量的推理测试(即固定效应)的能力不足。
结论
如果我们想知道我们的效果 是否存在——也就是说,即使研究的一个小方面发生了变化,被调查的心理过程是否发生并在现实世界中发挥作用,并且观察到的效果是否会复制——有必要随机选择项目(即刺激、目标、同盟者、学校、地点、环境),并在我们的数据分析中估计包含适当副项目随机效应的LMEM。
LMEM 非常适合分析独立或由某些更高阶单元(例如,治疗师内的患者)聚集的受试者随时间(或空间)的变化。LMEM 处理缺失数据更有效,因为与重复测量方差分析不同,它们不会消除具有一个或多个缺失值的受试者的所有观察结果。这是从 LMEM 到“广义线性混合 效应 模型”的一小步,当结果变量是分类、有序或计数时,这是需要的。
诸如方差分析和回归分析之类的标准统计程序是否已过时?绝对不是,因为仍然有许多心理学研究,其中预测变量因受试者而异,而受试者是唯一的随机变量。然而,我们经常让我们的受试者接触多个项目(例如,刺激、同盟者),检查它们如何随时间变化(例如,治疗、学习),在多种环境(例如,位置、情况)中测试它们,并与受试者打交道相互影响的人(例如,小组、教室)。鉴于这些类型的研究涉及多个非独立来源,LMEM 将越来越多地出现在我们科学期刊的结果部分中,并且无疑属于心理学研究人员的标准工具包。
文献3--面部分类的全有或全无神经机制:来自 N170 的证据
为了解开这些替代方案,我们采用线性混合模型 (LMM) 与零假设显着性检验 (NHST) 和等价检验 (ETs) 来检查 N170 对不同持续时间的面部和房屋图像的依赖性,而参与者报告每次试验的主观信心. 采取了几项措施来确保参与者在报告高主观信心时确实对面部有清晰的感知。[3]
为了解开这些替代方案,我们采用了线性混合建模(LMM),具有无效的假设显着性测试(NHST)和等效测试(ETS)来检查N170对面部和房屋图像的依赖性,而参与者则报告了每个试验的主观置信度。
材料和方法
受试者
35名受试者,仅在确定刺激为FAC的时候,按键1。
刺激
40张高加索人(20位女性)面孔的照片, 40套房屋图像。
设备
E-Prime 2.0,三星同步主HDTV显示器(60Hz),使用128通道AG/AGCL电极网,常见顶点(CZ)用作参考。
EEG数据处理
除了基于独立组件分析(ICA)结果拒绝独立组件(ICA)的结果外,所有步骤均使用新西兰Escience基础架构的高性能计算集群中的MATLAB脚本完成。(available: https://osf. io/fvtc3/)
程序
积分窗口、峰值通道和平均振幅
使用数据驱动的方法来确定N170和P1的窗口。
- 根据之前研究选择P7和P8作为可能的峰值通道。
- 总平均所有通道在刺激后100ms到250ms确定了这个这个大平均波形的最小(负)振幅。
- 定义了一个全宽半最大值的窗口,通过迭代调整窗口落在36-40ms的范围。
- 创建窗口的总平均头皮图,观察确认通道。负峰值活动中心在PO7和PO8附近。
- 用更新的峰值从新检查窗口。
- 确定ERP组件窗口内的平均振幅,交给LMM分析。
统计分析
线性混合建模
在本研究中应用 LMM 的具体好处是,与 rm-ANOVA 相比,LMM
可以在存在缺失数据的情况下产生无偏的结果,而无需移除参与者。LMM
的另一个优点是它们可以在单个观察级别上对幅度进行建模并估计多个随机效应。
为每个因变量获得最佳模型的一般程序遵循Bates、Kliegl 等人的建议[4]。
- 首先创建最大模型,包含所有受试者和项目的随机截距和随机斜率。
- 如果最大模型没有收敛,拟合相应的零相关模型,其中随机效应之间的相关性被强制为0。
- 然后没有显著解释数据的随机效应被零相关参数中移除,模型缩减。
- 再在简化模型中添加剩余随机效应之间的相关性来扩展模型,如果不能收敛,则将方差最小的随机效应逐一去除,直到模型收敛,从而得到最终的最优模型。
- 在此模型上进行后续比较。
软件
我们使用 R(R Core Team 2021)和 RStudio(RStudio Team 2021)进行了所有统计分析。使用 Tidyverse 软件包整理数据(Wickham 等人,2019 年)。我们使用 lme4 包 ( Bates, Mächler, et al. 2015b ) 执行 LMM,并使用 emmeans 包 (Lenth 2021 ) 进行后续比较和 ET,其中使用 Satterthwaite 近似来估计统计结果。R Markdown 输出文件可在https://osf.io/zv6kg/获得。
文献4--简约的混合模型
在过去的十年中,当将受试者和项目作为随机因素的变化时,心理语言实验的分析方式发生了重大变化(特别是从方差分析到线性混合模型(LMM))。尽管层次线性模型已经存在数十年了,但在Pinheiro和Bates(2000)之后的语言学和心理学等领域,它们在心理学和语言学等领域的采用变得更加广泛。最近,LMM的使用已扩散到其他心理学领域,例如人格和社会心理学。[4] 一个特别有吸引力的特征是,通过LMMS,有关实验效果和相互作用的统计推断不再需要单独的差异分析,一个针对受试者和项目,可以进行在一个连贯的框架内。
这种连贯性的好处是有一定代价的。使用混合效应模型分析实验数据的重要部分是选择适当的随机效应结构。原则上,LMM不仅考虑受试者之间的差异和因变量的平均值(即随机截距)的均值,而且在受试者之间以及所有主效应和交互作用(即随机斜率)以及项目之间的差异以及项目之间的差异(即随机斜率)以及截距和斜率之间的相关性。让我们使用最简单的模型来说明基本点,使用两级主题内实验操作,并使用主体作为唯一的随机因素,使用Bates等人描述的R的“ LME4”软件包的公式表示法。 (2015a):
1 | Y ~ 1 + A + (1|Subject) |
该模型可能支持受试者内因子A的固定效应A。但是,如果A(即两个实验条件之间的差异)在受试者之间可靠地不同,那么关于A的不确定性可能是如此之大,以至于以至于主要影响的主要影响A在模型中不再显着,允许A:
1 | Y ~ 1 + A + (1+A|Subject) |
为了评估实验操作的重要性,因此必须在存在相应的随机斜率的情况下检查其固定作用。
文献4--急性运动可改善甲基苯丙胺的渴望和抑制缺陷:一项ERP研究
渴望(carving)抑制缺陷(inhibitory deficts)
本研究采用受试者内平衡设计。共有 24 名参与者符合 DSM-IV 的MA 依赖标准被招募。渴望水平、反应时间和反应准确性,以及事件相关电位 (ERP) 成分 N2 和 P3,在运动和控制治疗后以平衡顺序进行测量。急性运动也促进了标准和 MA 相关的 Go/Nogo 任务的抑制性能。与阅读控制时段和 Go 条件相比,在锻炼时段和 Nogo 条件下的两项任务中观察到更大的 N2 幅度,但没有更大的 P3 幅度[5]。论文证明中等强度的急性运动对MA的渴望和抑制控制有益。
抑制是指不当行为或与任务无关信息的适应能力。
介绍
MA用户在多种认知表现指标上表现更差,例如抑制、执行能力、记忆和现实生活中的功能能力。抑制涉及多个大脑区域,包括额下叶、顶叶和基底神经节。长期滥用MA会导致与抑制相关的大脑功能区域障碍,例如前扣带皮层(ACC)和背外侧前额叶皮层(DLPFC)。
N2被认为代表了一个冲突监测过程,相对于健康组,滥用药物组观察到较低的N2振幅。
P3振幅被认为代表了上下文更新、注意力资源分配以及促进检测和评估刺激的过程,与N2类似,具有物质依赖的个体在皮质抑制相关的任务间表现出降低的P3振幅。
大量研究发现,在健康人群中停止中等强度的急性有氧运动后,需要抑制控制的任务条件下,认知能力的增强都与P3振幅增强有关。
方法
参与者
24名18-40岁参与者(20男,4女),根据DSM-IV标准,排除1)精神病史 2)身体或医疗状况 3)色盲 4)Raven的智力测试标准。
渴望评估
视觉模拟量表(VAS)。
认知任务
使用两个Go/Nogo范式,Go: MA-Go(蓝框MA), Neutral-Go(蓝框中性); Nogo: MA-Nogo(), Neutral-Nogo。
EEG处理
N2和P3量化为200ms-300ms和300-500ms之间。分别来自于Fz、Cz、Pz的电极。
统计分析
- VAS:为了检查参与者的渴望状态,应用 2(会话:运动,控制) × 4(时间点:运动前、运动中、运动后立即、 运动后 50 分钟)重复测量方差分析来评估 VAS 分数。
- 关于神经电数据,对于标准 Go/Nogo 任务,2(会话) × 2(条件) × 3(站点:Fz、Cz、Pz)ANOVA 分别针对 N2 幅度、N2 潜伏期、P3 幅度和 P3 潜伏期进行。
相关网页链接
论文:
R语言:
教程
[讲座/北理工]R语言入门-线性混合模型分析_王蓓老师_200824
INTRODUCTION TO LINEAR MIXED MODELS
线性混合效应模型入门之一(linear mixed effects model)
线性混合效应模型入门之二 - 实例操作及结果解读(R、Python、SPSS实现)
线性混合效应模型入门之二 - 实例操作及结果解读(R、Python、SPSS实现)
SPSS
【心理学实验】SPSS两因素重复测量方差分析 简单效应分析(有代码在评论里)